
API 설계가 기술 부채를 결정한다
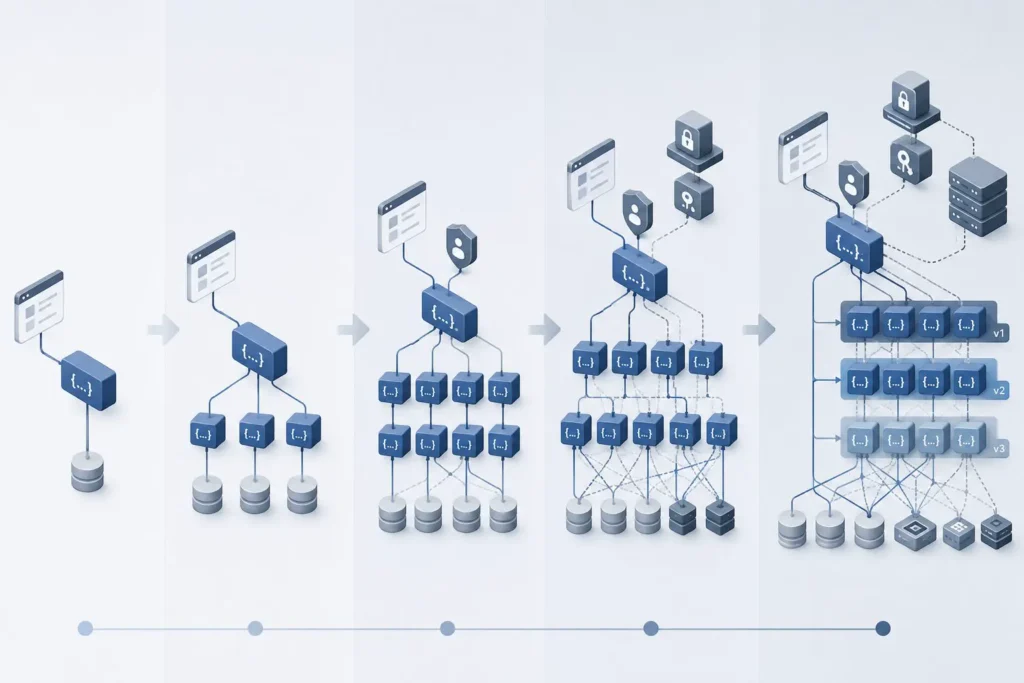
기술 부채는 대부분 코드에서 시작된다고 생각하기 쉽다. 하지만 실제 운영 환경에서는 API 구조가 훨씬 오래 문제를 남기는 경우가 많다. 코드 내부는 리팩토링으로 정리할 수 있어도 외부에 공개된 API 인터페이스는 쉽게 바꾸기 어렵기 때문이다.
초기 서비스에서는 빠른 개발이 우선이다. 기능을 먼저 붙이고 화면을 연결하는 과정에서 API는 자연스럽게 늘어난다. 문제는 초기 기준 없이 만들어진 API가 시간이 지나면서 유지보수 구조 자체를 복잡하게 만든다는 점이다.
처음에는 단순했던 엔드포인트가 점점 복잡해지고, 응답 포맷이 서비스마다 달라지고, 인증 방식이 섞이기 시작한다. 이후 새로운 기능이 추가될수록 기존 구조와 충돌이 발생한다.
특히 SaaS, AI 플랫폼, 모바일 서비스처럼 외부 연동이 많은 환경에서는 API 구조 자체가 시스템 안정성을 결정하는 경우도 많다. 실제 장기 운영에서는 코드 자체보다 인터페이스 호환성 유지 비용이 더 크게 늘어나는 경우가 많다.
좋은 API 설계는 단순히 “예쁜 REST 구조”를 만드는 문제가 아니다. 장기적으로 시스템을 얼마나 안정적으로 확장할 수 있는지를 결정하는 문제에 가깝다.
많은 시스템이 API 단계에서 이미 복잡해지기 시작한다
초기 프로젝트에서는 API 설계보다 기능 구현이 우선되는 경우가 많다. 화면을 빨리 연결해야 하고 서비스 흐름을 먼저 검증해야 하기 때문이다.
문제는 이 과정에서 구조 일관성이 빠르게 무너진다는 점이다. 어떤 API는 /user/list 형태이고 어떤 곳은 /users 형태로 만들어진다. 응답 구조도 서비스마다 달라진다. 에러 코드 규칙 역시 통일되지 않는 경우가 많다.
초기에는 큰 문제가 없어 보인다. 하지만 서비스 규모가 커지고 협업 인원이 늘어나면 이런 차이가 유지보수 비용으로 이어지기 시작한다.
특히 마이크로서비스 환경에서는 이런 차이가 운영 난이도로 직접 이어지기 쉽다.
| 상황 | 시간이 지나며 발생하는 문제 |
|---|---|
| 응답 구조 불일치 | 프론트엔드 수정 비용 증가 |
| API 네이밍 혼재 | 신규 개발자 이해 속도 저하 |
| 에러 포맷 비통일 | 디버깅 시간 증가 |
| 인증 방식 혼합 | 보안 정책 관리 어려움 |
실제로 많은 조직이 “기능은 빠르게 만들었는데 API 구조가 너무 복잡해졌다”는 문제를 겪는다. 초기에는 단순히 개발 속도를 높이기 위한 선택이었지만 시간이 지나면서 구조적 기술 부채로 바뀌는 것이다.
좋은 API는 기능보다 일관성을 먼저 만든다
좋은 API 설계의 핵심은 기능보다 일관성이다. 기능 자체는 시간이 지나면서 계속 바뀔 수 있지만 구조 기준은 장기적으로 유지되기 때문이다.
대표적인 예가 URI 규칙이다. /users/{id} 같은 리소스 중심 구조를 유지하면 API 목적을 직관적으로 이해하기 쉬워진다. 반대로 /getUserInfo, /updateUserData처럼 기능 중심 이름이 섞이기 시작하면 구조 일관성이 빠르게 무너질 수 있다.
응답 포맷 통일도 중요하다. 어떤 API는 data 필드를 사용하고 어떤 곳은 result를 사용하면 클라이언트 로직이 복잡해진다.
실무에서는 OpenAPI 기반 문서화가 중요하게 다뤄지는 이유도 여기에 있다. API 스펙을 명확하게 관리하면 협업 충돌을 줄일 수 있기 때문이다.
다음 요소는 장기 유지보수에서 특히 중요하게 작용한다.
- URI 규칙 통일
- 응답 포맷 표준화
- 에러 코드 체계 정리
- OpenAPI/Swagger 문서화
- Contract-first 설계
- Schema validation 적용
특히 Swagger 기반 contract-first 방식을 도입한 이후 프론트엔드와 백엔드 간 수정 충돌이 크게 줄어드는 사례도 많다.
좋은 API는 단순히 “동작하는 API”가 아니다. 다른 서비스가 연결돼도 예측 가능하게 동작하는 구조에 가깝다.
버전 전략이 없으면 운영 비용이 빠르게 커진다
API 기술 부채에서 가장 자주 등장하는 문제 중 하나가 버전 관리다.
초기 서비스에서는 대부분 v1 구조로 시작한다. 하지만 시간이 지나면서 응답 구조가 바뀌고 필드가 추가되기 시작한다. 문제는 기존 클라이언트와의 호환성이다.
특히 모바일 앱은 문제가 더 크다. 사용자가 최신 버전을 즉시 설치하지 않기 때문에 오래된 API 구조를 함께 유지해야 하는 경우가 많다. 실제로 구버전 앱 호환 때문에 v1 API를 수년 동안 유지하는 사례도 드물지 않다.
많은 조직이 단순히 /v1, /v2 형태만 추가하면 해결된다고 생각한다. 하지만 실제로 중요한 것은 backward compatibility 관리다.
예를 들어 다음 변경은 예상보다 큰 영향을 만들 수 있다.
- 필드 이름 변경
- 응답 타입 수정
- 필수 값 추가
- 인증 방식 변경
- 응답 구조 계층 수정
실무에서는 API 변경보다 “API 변경 이후 운영 비용”이 더 큰 문제로 이어지는 경우가 많다. 특히 연동 서비스가 많을수록 수정 범위가 급격히 커진다.
그래서 최근에는 API Gateway 기반 버전 관리나 schema validation 구조를 함께 사용하는 경우가 늘어나고 있다.
인증과 권한 구조는 뒤늦게 붙일수록 위험해진다
많은 서비스가 초기에는 단순 인증 구조로 시작한다. 빠른 개발이 우선이기 때문이다.
문제는 서비스 규모가 커진 뒤 인증 체계를 다시 정리하려고 하면 구조 충돌이 매우 크게 발생한다는 점이다. 특히 API마다 인증 방식이 달라지기 시작하면 운영 난이도가 급격히 올라간다.
대표적인 예가 JWT 기반 인증이다. 초기에는 간단해 보이지만 권한 체계가 복잡해질수록 토큰 관리와 만료 전략이 중요한 문제가 된다.
OAuth 역시 마찬가지다. 외부 서비스 연동이 늘어나면 인증 흐름 자체가 시스템 핵심 구조가 된다.
최근에는 API Gateway를 중심으로 인증과 권한 관리를 통합하는 구조가 많이 사용된다.
| 인증 구조 | 장기 운영 시 특징 |
|---|---|
| 서비스별 인증 구현 | 유지보수 복잡도 증가 |
| JWT 기반 통합 인증 | 확장성은 좋지만 관리 전략 중요 |
| OAuth 기반 연동 | 외부 서비스 확장에 유리 |
| API Gateway 중앙 관리 | 정책 일관성 유지 가능 |
특히 SaaS 구조에서는 조직 단위 권한, 사용자 역할, API 접근 범위가 계속 추가되기 때문에 초기 권한 모델 설계가 중요해진다.
API 구조가 팀 협업 속도까지 결정하는 이유
API는 단순한 데이터 전달 수단이 아니다. 팀 간 협업 인터페이스 역할도 함께 한다.
프론트엔드는 API 구조를 기준으로 화면을 개발하고, 백엔드는 데이터 구조를 정의한다. 데이터팀은 분석 이벤트를 연결하고 외부 파트너는 API 문서를 기준으로 연동을 진행한다.
문제는 API 기준이 명확하지 않으면 협업 비용이 급격히 증가한다는 점이다.
특히 빠른 개발 문화에서는 다음 문제가 반복되기 쉽다.
- 프론트엔드 요청마다 임시 필드 추가
- API 문서보다 실제 응답이 우선됨
- 서비스별 응답 규칙이 계속 달라짐
- 레거시 모바일 앱 때문에 오래된 API 유지
- 수정 범위 예측이 어려워짐
실제로 많은 조직에서 API 변경 회의 자체가 병목이 되는 경우도 있다. 서비스마다 규칙이 다르면 새로운 기능 추가 때마다 충돌이 발생하기 때문이다.
최근에는 contract-first 설계와 schema registry를 함께 사용하는 경우도 늘어나고 있다. 단순 구현 중심 개발보다 협업 안정성을 우선하는 흐름이 강해지는 것이다.
결국 API 구조는 코드 스타일보다 조직 커뮤니케이션 비용에 더 직접적인 영향을 미친다.
기술 부채는 코드보다 API에서 오래 남는다
코드는 내부 구조라서 리팩토링이 가능하다. 하지만 API는 외부와 연결된 계약에 가깝다. 한 번 공개된 인터페이스는 쉽게 바꾸기 어렵다.
특히 외부 고객이나 파트너가 사용하는 API는 영향 범위가 매우 크다. 단순 필드 변경 하나만으로도 여러 서비스가 동시에 장애를 겪을 수 있다.
그래서 API 기술 부채는 시간이 지날수록 더 무거워지는 경우가 많다. 오래된 API를 제거하지 못하고 계속 유지하게 되면서 운영 비용이 누적된다.
실제로 장기 운영 시스템에서는 코드보다 “호환성 유지 비용”이 더 커지는 경우도 많다. 새로운 기능 개발보다 기존 API 구조를 유지하기 위한 작업이 더 많아지는 상황이다.
좋은 API 설계는 미래 확장을 완벽하게 예측하는 작업이 아니다. 변경이 발생하더라도 충돌을 최소화할 수 있는 구조를 만드는 일에 가깝다.
결국 기술 부채는 단순 코드 품질 문제가 아니다. 시스템이 얼마나 안정적으로 진화할 수 있는가를 결정하는 구조 문제다.
